Quantifying AI Threat Capability
In the rapidly evolving landscape of artificial intelligence, distinguishing between hypothetical threats and tangible AI Security (AISec) threats has never been more critical. As AI technologies grow more sophisticated, so too do the potential security threats they pose, from deepfakes disrupting public understanding, to AI-powered cyber-attacks targeting critical infrastructure.
However, not all threats carry the same weight of immediacy or potential for harm. Amidst a sea of speculation and sensationalism, it becomes paramount to separate fearmongering from genuine threats. We must adopt a more scientific approach to understanding cybersecurity threats in an AI-driven world.
What is AI Security?
AI Security can be described as the range of tools, strategies, and processes employed to identify and prevent security attacks that could jeopardise the Confidentiality, Integrity, or Availability (CIA) of an AI model or AI-enabled system. It is a crucial element of the AI design and development cycle, ensuring safe and consistent performance throughout its operation.
In addition to traditional cybersecurity vulnerabilities, the integration of AI into systems introduces new threat vectors and vulnerabilities, necessitating a fresh set of security protocols. A threat-centric approach using the Capability Matrix will facilitate critical decisions that need to be made by leaders to triage and prioritise resources to mitigate against these threats.
Why do we need to understand Threat Capability?
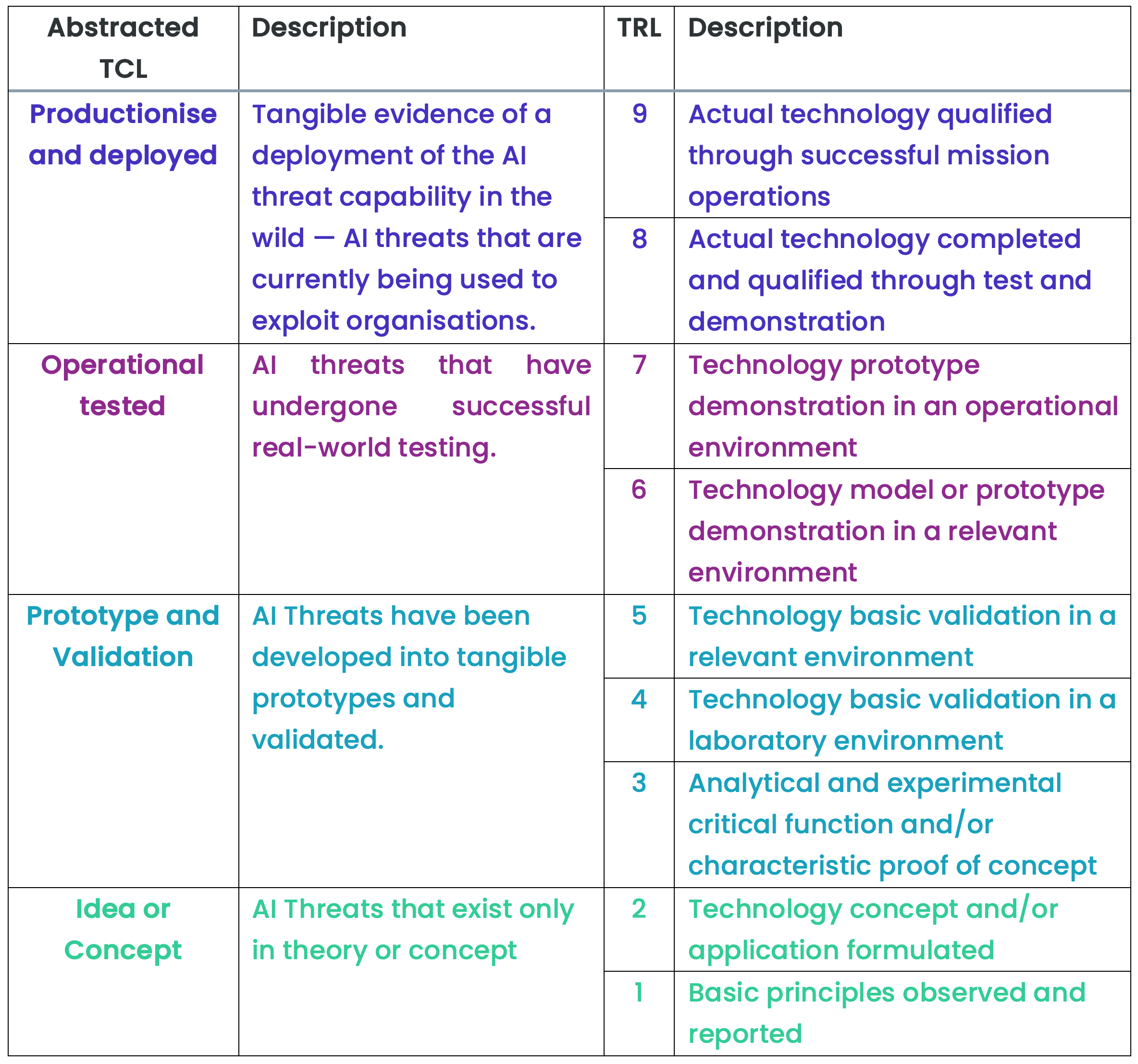
By adopting a threat-centric evidence-based methodology, we can examine each AI threat vector based on its current capability, separating what is theoretically possible from what is empirically evident. This approach provides a method to distinguish between four distinct stages of AI threat capability development:
- Idea or Concept, AI threats that exist only in theory
- Prototype and Validation, AI threats that have been developed into tangible prototypes and validated
- Operationally Tested, AI threats that have undergone successful real-world testing
- Productised and Deployed, Tangible evidence of a deployment of the AI threat capability in the wild
The four abstracted AI Threat Capability Levels (TCL) have been mapped to what is known in Defence as the Technical Readiness Levels (TRL), a standard used to develop military warfighting capabilities. The purpose of adding this extra level of detail is to provide a more granular understanding of the maturity of each threat capability.
What is the MITRE ATLAS ATT&CK Framework?
The MITRE ATLAS ATT&CK matrix is an AI security framework to understand how each AI threat vector maps to a kill chain from early reconnaissance to the effect or impact on target. The ATLAS AI Security framework enables a comprehensive understanding mapping to the more sophisticated AI security cyber threats.
Here's an overview of each threat attack or kill chain stage:
Reconnaissance
Adversaries aim to collect information about the AI system they are targeting to plan their future operations. Reconnaissance involves techniques where adversaries actively or passively gather information that supports targeting, such as details of the victim organisation's AI capabilities and research efforts.
Resource Development
Adversaries seek to establish resources to support their operations. This includes acquiring infrastructure, capabilities, and developing or obtaining AI-specific tools and techniques needed to conduct their campaign.
Initial Access
Adversaries attempt to gain an initial foothold within a network or AI system. Techniques include spear-phishing targeted at AI researchers, exploiting public-facing applications that use AI, and supply chain compromise.
ML Model Access
Adversaries attempt to gain access to the target AI model, either through direct API access, physical access to hardware, or by compromising the development or deployment environment.
Execution
Adversaries run malicious code or manipulate model inputs. In the context of AI, this includes prompt injection attacks, adversarial inputs, and model manipulation.
Persistence
Adversaries try to maintain their foothold in the AI system or infrastructure. Techniques include model backdoors, data poisoning that survives retraining, and persistent access to training pipelines.
Privilege Escalation
Adversaries attempt to gain higher-level permissions. The objective is to obtain elevated access such as system-level or administrator privileges, exploiting system weaknesses, misconfigurations, and vulnerabilities.
Defence Evasion
Adversaries strive to avoid detection by AI-enabled security software, employing techniques to bypass malware detectors and similar security solutions, often overlapping with persistence strategies to maintain stealth.
Credential Access
This stage involves stealing credentials like account names and passwords through keylogging, credential dumping, or other methods, facilitating system access and making detection more challenging.
Discovery
Adversaries seek to understand the AI environment, using techniques to learn about the system and network post-compromise. This helps in planning subsequent actions based on the environment's characteristics and potential control points.
Collection
Adversaries collect data of interest to their goal. In AI contexts, this includes exfiltrating training data, model weights, or the proprietary outputs of AI systems.
Exfiltration and Impact
The final stages involve removing data from the environment and achieving the primary objective, whether financial gain, disruption of services, or degradation of AI system performance.
How to use the AI Security Threat Capability Matrix
For this example, we will use a case study where an AI Security vulnerability was exploited at a cost of $77 million to a government organisation, the Camera Hijack Attack on a Facial Recognition System.
This example illustrated a successful breach of an AI facial recognition authentication system, allowing a malevolent threat actor to gain entry, manipulate an AI model to facilitate their attack, and abscond with $77 million.
Employing this methodology, additional case studies can be presented on cyberattacks against AI systems. In some case studies, utilising the Threat Capability Matrix shows that certain AI security breaches are purely theoretical, or have only been corroborated in a laboratory environment, underscoring the absence of evidence for these capabilities being deployed in the real world.
Why does this matter for leaders?
Facilitates AI Integration: AI and machine learning models in cybersecurity stand to gain significantly from standardised definitions within the threat capability matrix. Such models can automatically categorise threats within a cybersecurity data fabric, boosting the speed and precision of threat detection and response.
Encourages Collaborative Defence: A scientifically robust approach to the threat capability matrix fosters collaboration across various sectors and industries. This mutual effort allows for the exchange of threat intelligence and defensive strategies, strengthening the collective cybersecurity posture.
Distinguishing Theoretical vs Actual Capabilities: Understanding the matrix aids in differentiating between theoretical threats and those that threat actors currently possess, enabling more accurate risk assessments and better allocation of defensive resources.
Optimises Resource Allocation: Being aware of the present capabilities of threat actors allows organisations to distribute their cybersecurity resources more effectively. By concentrating efforts on immediate threats, organisations can improve their defence against actual, as opposed to hypothetical, attacks.
Guides Defence Capability Development: A clear understanding of the matrix empowers cybersecurity teams to create more focused and potent defence mechanisms. Preparedness for potential threat escalations ensures that defences are proactive, not just reactive.